Anomaly Detection Paper Summary
Anomaly Detection Paper Summary
Reconstruction Based Methods
这种方法主要用于无监督的异常检测。通过神经网络重建输入图像,并以最小化重建图像和输入图像间的差距作为训练目标,来学习图像的特征信息,进而检测出异常图像。因为我们用正常图像训练网络,所以在测试的时候,我们认为输入的正常图像可以被顺利地重建出来;而对于异常图像,由于神经网络在训练时没有见过,很难重建出和原图相似的图像。换言之,这种重建误差就是异常图像的判断标准。对于某输入图像而言,重建误差越大,则该图像是异常图像的可能就越大
-
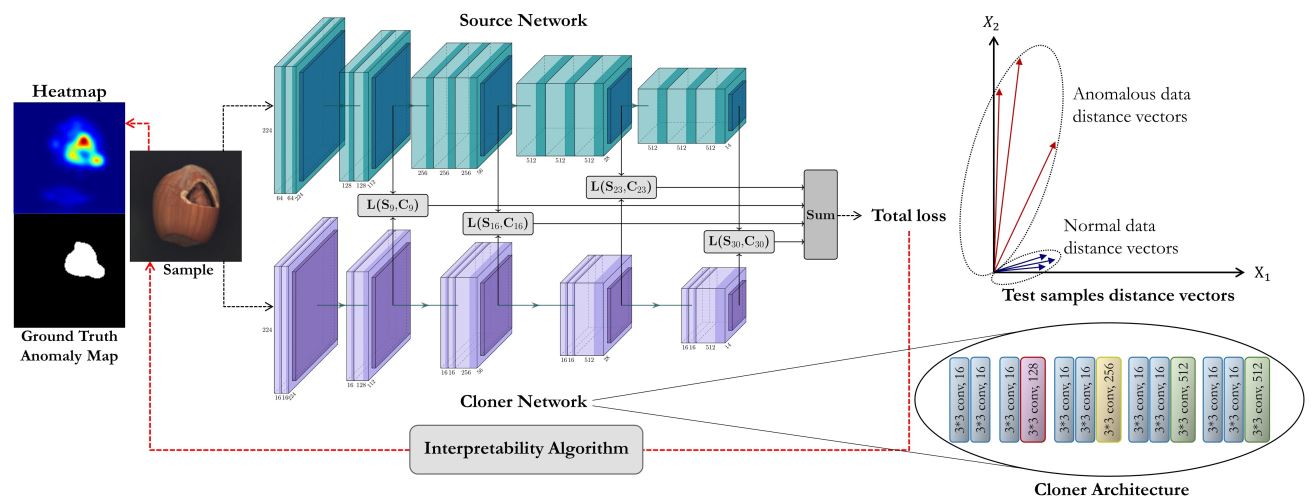
DAE:Anomaly Detection Using Autoencoders with Nonlinear Dimensionality Reduction
利用 AutoEncoder 重建图像,重建图像与原始图像的 L2 距离加上线性层的权重正则作为训练目标。
-
相比于原始的 AutoEncoder 架构,增加了一个 memory module M。这个模块用来记录输入的正常图像中最具代表性的若干模式(随着训练不断更新),每个模式和隐变量的维度相同。对于 encoder 输出的隐变量 Z, 不是直接输入 decoder 重建图像,而是输入到 memory module,通过attention的方式得到 M 中各个模式的加权组合作为新的隐变量 Z’ ,再输入到 decoder 中得到重建图像。
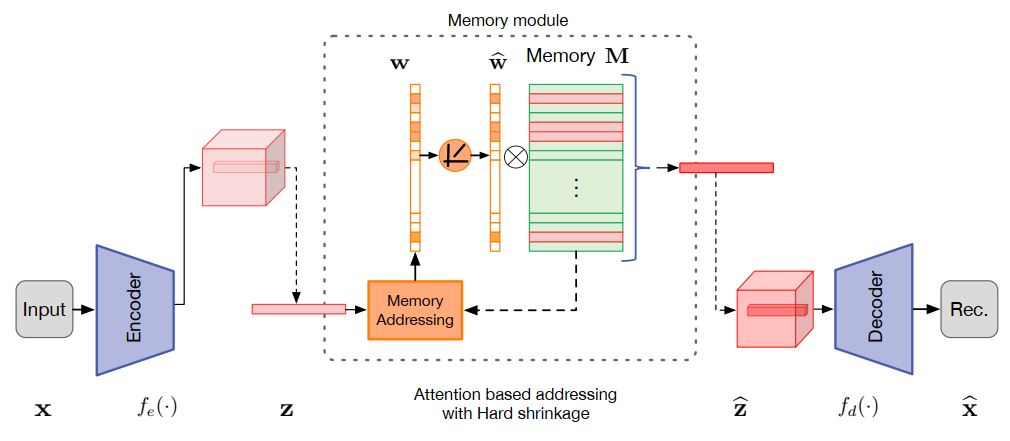
这种方法的原理在于强化对异常图像的检测能力。通过这种 memory module,神经网络可以将正常的图片中的关键特征更好地映射到隐变量空间。对于异常图像,则很难通过该模块得到包含各种正常图像特征的隐变量,进一步扩大了重建误差,使其能够更容易地被区分出来。
-
MemSTC:Memorizing Structure-Texture Correspondence for Image Anomaly Detection
采用若干个 encoder-decoder 结构,针对提取的结构特征和边缘特征进行重建。最后将重建的这两个特征图像与原图像提取的attention信息进行结合得到最终的重建图像。
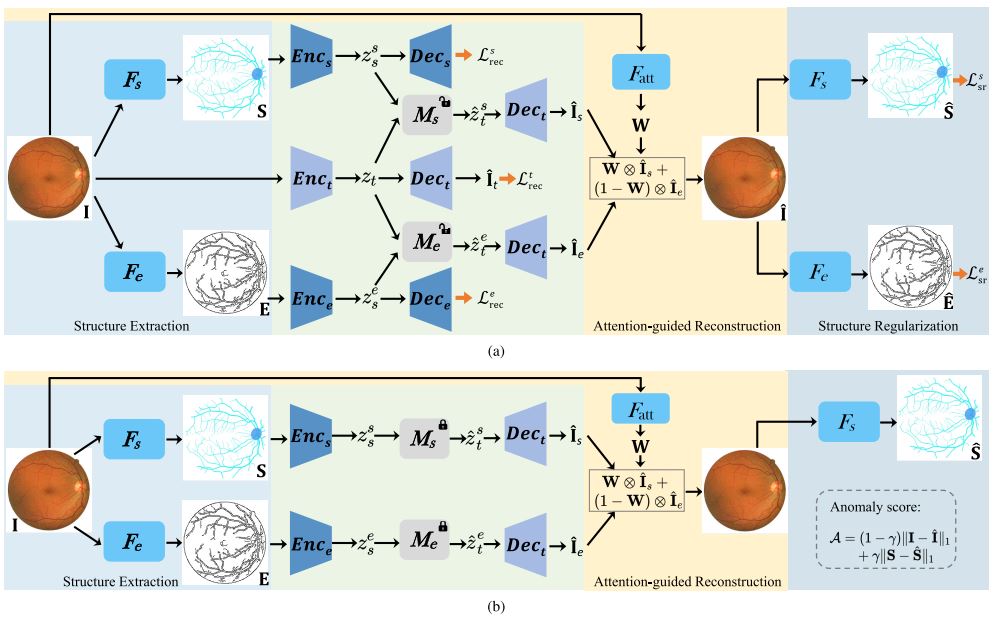
这篇论文的特点在于也采用了 memory module。不过和 MemAE 中的结构不同,这里的记忆模块不是可训练参数,而更像是队列这种数据结构,里面存储大量的(2048个)键值对。key 是结构提取网络得到的结构特征,value 是图像 encoder 之后的隐变量特征。在测试时将 memory module 中最接近的结构特征作为 key,将对应的value输出到decoder得到子重建图像
-
Skip-GANomaly: Skip Connected and Adversarially Trained Encoder-Decoder Anomaly Detection
类似于 ALOCC,同样是结合了重建网络和判别网络,并采用 GAN 的方式进行训练。不同的是,这里测试时主要利用的是重建网络,判别网络此时用于提取原图像和重建图像隐变量特征空间(取最后一层卷积的输出)。将图像重建误差与对应的feature map误差的和作为检测异常的标准
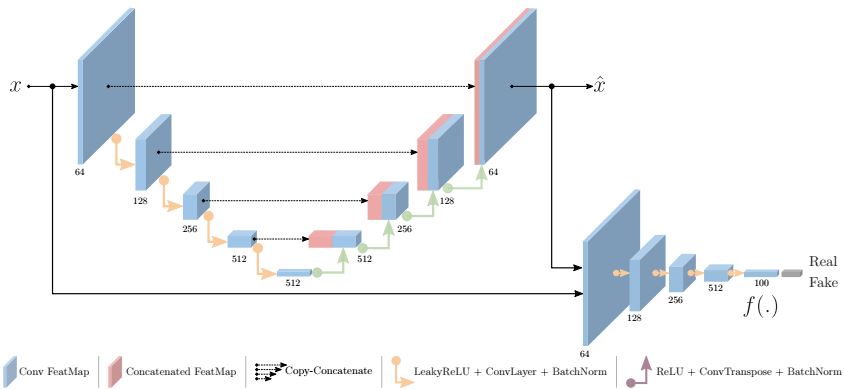
这篇论文的原理在于分别利用重建网络和判别网络,同时重建图像空间和特征空间,期望模型能够在图像空间或者特征空间上成功地重建正常图像。
-
OCGAN: One-class Novelty Detection Using GANs with Constrained Latent Representations
这篇论文针对一个问题:如何保证从隐空间内采样后再经过 decoder 得到的图像一定是类内图像?为此,该论文提出了OCGAN网络框架,包含一个auto-encoder、两个判别器和一个分类器
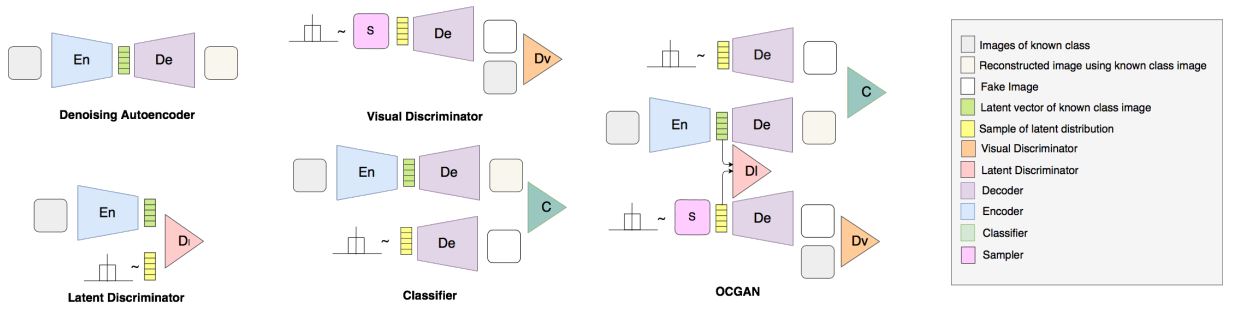
auto-encoder用来将原始图像变换到隐空间,再通过decoder重建图像。第一个判别器用来判别隐空间内均匀随机采样的隐变量和原图像经过encoder得到的隐变量。第二个判别器用来判别隐空间均匀随机采样的隐变量重建后的图像和原始图像。这两个判别器与生成器通过 GAN 的方式训练。
但此时仍然无法保证类内图像。因为隐空间太大了,随机采样会有漏网之鱼,又不可能遍历整个隐空间。我们也不能简单地降低隐空间维度,这会降低异常检测的性能。论文中采用的方法是Informative-negative Mining,主动从隐空间寻找导致低质量图像的区域,用这些区域内的样本训练生成器,用随机采样训练判别器。
寻找方法是利用一个分类器,评估在当前隐空间中的位置采样后生成的图像质量,利用损失函数的梯度方向移动到隐空间内的新区域。在这个新区域中,分类器更有信心地认为对应的生成图像是类外图像。这个分类器的训练和 GAN 训练框架是迭代串行的,因此不会影响到生成器和判别器的参数更新。训练时,将正常图像的重建图像作为正样本,隐空间随机采样生成的图像作为负样本监督这个分类器。
Restoration Based Methods
这种方法是对原始图像进行一些干扰操作(裁剪,消除,旋转等),通过神经网络恢复输入图像,并以最小化恢复图像和原始图像间的差距作为训练目标。这种方法类似于重建方法,测试时同样对图像进行不同的干扰操作,利用恢复误差判断图像的异常程度。此外,这种方法还可以用来定位异常区域。
-
SMAI:Superpixel Masking and Inpainting for Self-Supervised Anomaly Detection
采用 SuperPixel 技术,首先将图像划分为像素块。随机去除若干像素块,输入到恢复网络中期望得到复原图像,用原始图像与复原图像之间的 SSIM 指标作为训练目标。
在测试时,对于某张测试图像,分别去除单个像素块得到一个对应的测试集输入网络。利用 SSIM 或者 L2 距离衡量异常程度。最后将测试集的衡量指标求和,得到该测试图像的异常分数。
这篇论文的原理在于,对于正常区域的像素块,恢复网络可以成功地恢复出来,对应的恢复误差很小。而对于包含异常区域的像素块,恢复网络因为没见过,只能恢复成正常区域,导致较大的恢复误差。这样分别考虑去掉各个像素块的情况,就可以根据恢复误差定位出异常区域。
-
SCADN:Learning Semantic Context from Normal Samples for Unsupervised Anomaly Detection
这里采用条纹状的 mask 去除原始图像中的区域,输入到恢复网络中期望得到复原图像。针对条纹的粗细,方向等分为不同的 mask 类型,每次对训练图像随机选择一种mask进行叠加。训练时,增加一个判别器,用来判别原始图像和恢复图像。判别器和恢复网络通过 GAN 的方式进行训练。
测试时,分别将各类不同粗细的mask作用于测试图像。每类mask中,又包括不同方向和排列顺序的mask,选择恢复误差最大的 error map 作为该类 mask 作用后的结果。在不同类的 mask 中选择平均距离最大的 error map 对应的均值作为检测异常的标准。
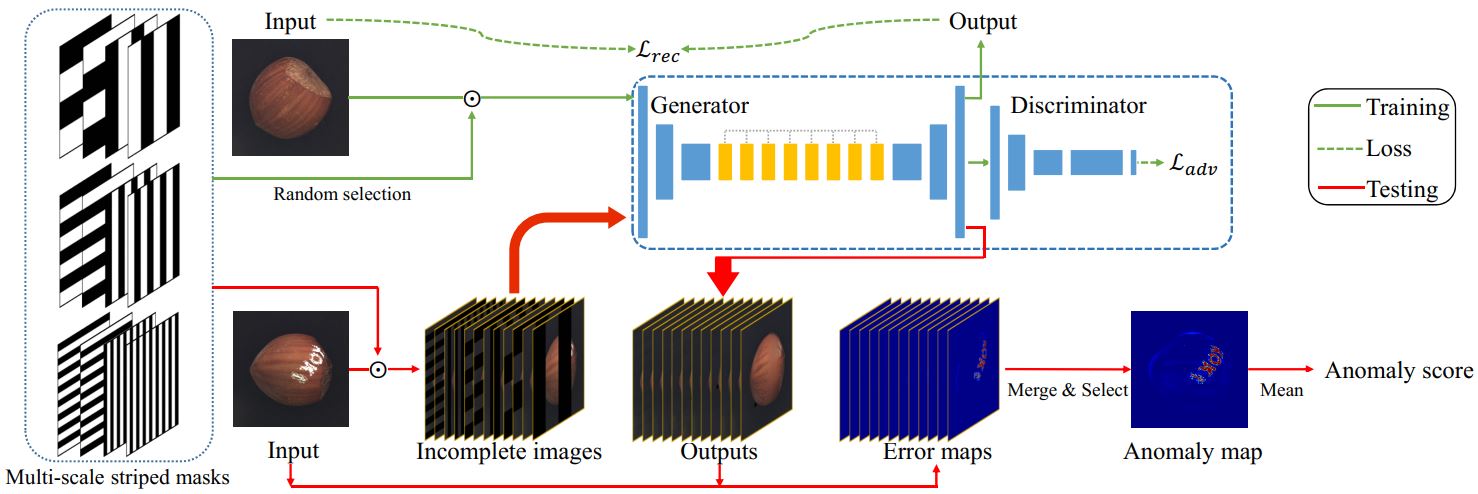
这篇论文的特点在于采用条纹状的 mask 进行遮盖。这种mask保证了所有图像区域被同等概率地遮盖,同时考虑了异常区域各种可能的大小和方向。
Embedding Based Methods
这种方法主要是利用神经网络对图像提取特征,然后根据 feature map 层面的向量进行处理比较,进而实现异常检测。这种方法的原理是,异常图像在图像层面可能很难被检测出来,但可以通过投影到另一个表示空间。在新的空间层面下,异常样本可以被明显地划分出来
-
Anomaly Detection in Nanofibrous Materials by CNN-Based Self-Similarity
这篇论文将输入图像切分为patch输入网络,将输出的特征向量通过PCA降维后再利用 K-means 聚类得到一个字典。测试时按相同的流程得到测试图片某个patch的降维特征向量,与字典中的每一项分别计算欧氏距离,用平均值作为检测异常标准。

Discrimination Based Methods
这种方法的大部分是采用一个 one-class 的分类器,用来区分正常图像和异常图像。并将分类器的输出值作为输入图像的异常程度。
-
ALOCC:Adversarially Learned One-Class Classifier for Novelty Detection
这篇论文结合了重建网络和判别网络。首先将原始图像输入重建网络,得到重建图像。接着利用判别网络来判别该图像属于重建图像还是原始图像。这两个网络通过 GAN 的方式进行训练。测试时,可以直接用判别网络作用于测试图像来确定异常程度,也可以用判别网络作用于重建图像来确定异常程度,后者效果会更好一些
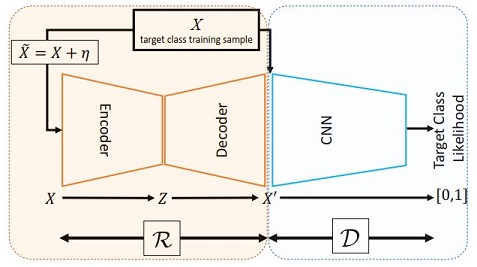
这种方式实际上是通过重建网络制造负样本,即将所有的重建图像视为异常图像,原始图像视为正常图像,用来监督判别网络的训练。利用训练得到的判别网络进行异常检测。
-
GeoTrans:Deep Anomaly Detection Using Geometric Transformations
这篇论文利用自监督的方法,人为制造出训练图像的标签。对图像进行不同的几何变换操作并输入网络,变换操作的类型作为图像标签,期望网络能够成功分类出应用在当前图像上的变换操作类型。测试时,将训练中可能出现的各种变换方式分别应用在测试图像上,结合这些输出的分类结果作为异常检测的标准。
对于网络输出的分类预测结果,该论文采用 Dirichlet Normality Score 将其转化为异常分数。对于图像变换的选择,该论文采用水平翻转、平移和旋转的72种不同组合。之所以没有选择高斯模糊等非几何变换,是因为可能会消除掉图像中的某些重要特征,对性能造成影响。
这种方法的原理在于,网络在识别出变换方式的过程中,能够提取出不同变换下的原图像特征,此时的图像特征就认为是该类图像的典型特征。那么对于异常图像,则很难提取出同样的这些特征,很难判断应用其中的几何变换方式,就可以被检测出来。
Knowledge Distillation Based Methods
这种方法采用知识蒸馏,将 teacher 网络的知识迁移到规模较小的 student 网络。利用 teacher 与 student 之间性能差异作为检测异常的标准。也即是说,这种方法认为 teacher 能够提取包括异常图像在内的特征;而 student 只学到了 teacher 关于正常图像的知识,仅能提取正常图像的特征。
-
MKD:Multiresolution Knowledge Distillation for Anomaly Detection
这篇论文利用知识蒸馏,同时考虑两个网络间的多个中间层输出的欧氏距离作为训练目标。与此同时,还考虑了中间层向量的方向,用中间层输出的余弦距离作为损失函数的正则项。该损失函数的值同样用于测试时的异常程度判断。
此外,利用Loss对输入图像的梯度,结合腐蚀与膨胀等操作,可以定位异常区域。